
The Story of Databricks - Why it exists?
From One Machine to Hadoop to Spark and the Rise of the Databricks Data + AI Platform

Hey friends, Happy Tuesday!
I just published the first video in a new series where I’ll be sharing everything I know about Databricks!! 🎉
For the past 5 years, I’ve been building data projects almost entirely on one platform: Databricks. And honestly, it worked like magic.
So now I want to share everything I’ve learned from those years of building real projects.
But if you know my style, you know I don’t like jumping straight into a tool or platform… I like to start with the foundations.
The big questions: What is it? Why does it exist? Who is it actually for?
The interesting thing is that this platform is not only for data engineers anymore.
Today it’s used by data analysts, data scientists, ML engineers, and even AI engineers.
let’s start with the story.
The Single Machine Era
In the beginning, everything ran on a single machine.
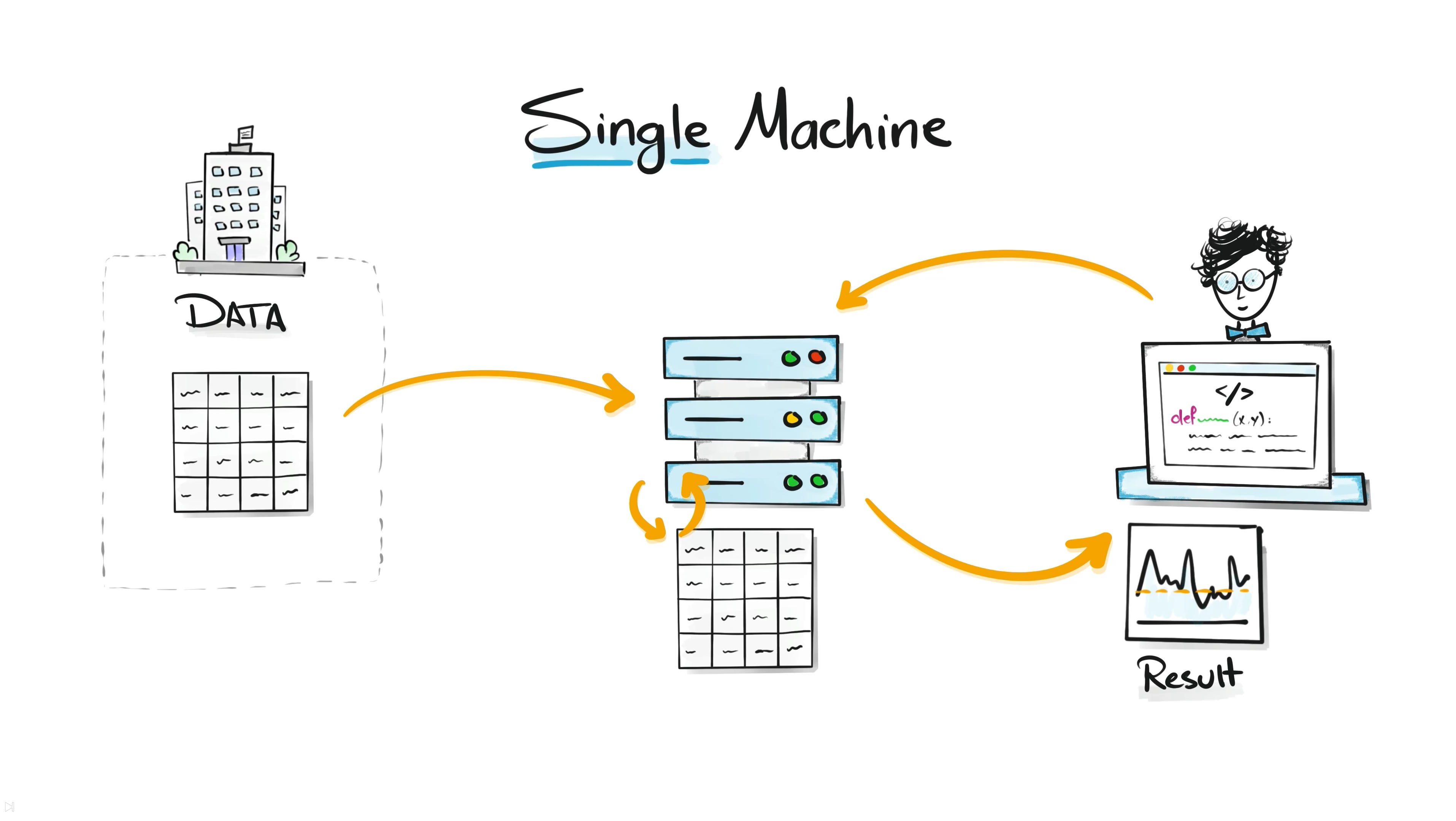
Companies stored their data on one server and analysts or engineers ran SQL queries or Python scripts to analyze it. For small datasets this worked perfectly. The machine had enough CPU, memory, and storage to process everything.
But as companies digitized more of their business, data volumes exploded. Websites started generating event logs. Applications produced telemetry. Businesses began storing historical records for years.
Suddenly data grew from gigabytes to terabytes.
One machine was no longer enough. Queries took hours. Systems crashed under heavy workloads. And if that single machine failed, the entire analytics process stopped.
One computer works for small data, but it collapses when data becomes massive.
The Hadoop Era
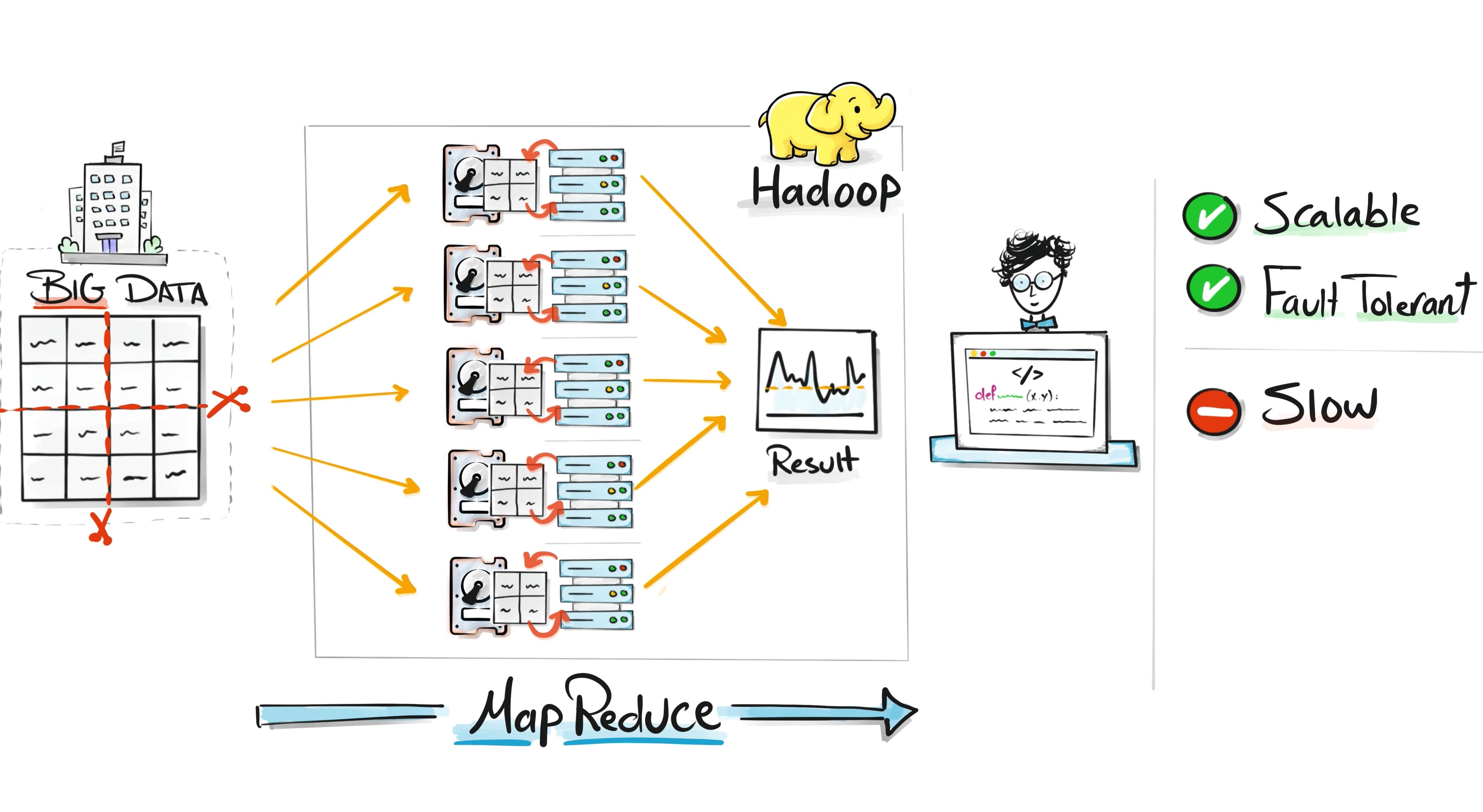
To solve this scaling problem, Hadoop introduced distributed computing.
Instead of relying on one powerful computer, Hadoop used many smaller machines working together in a cluster. Data was split across those machines, and each machine processed its piece in parallel.
This approach allowed companies to process massive datasets that were impossible to handle before.
But Hadoop had a big drawback.
Every computation required reading data from disk, processing it, and writing it back to disk again.
Disk operations are slow compared to memory. As datasets grew larger, Hadoop jobs could take hours or even days to complete.
Hadoop solved the scaling problem, but processing data from disk made everything slow.
The Spark Era
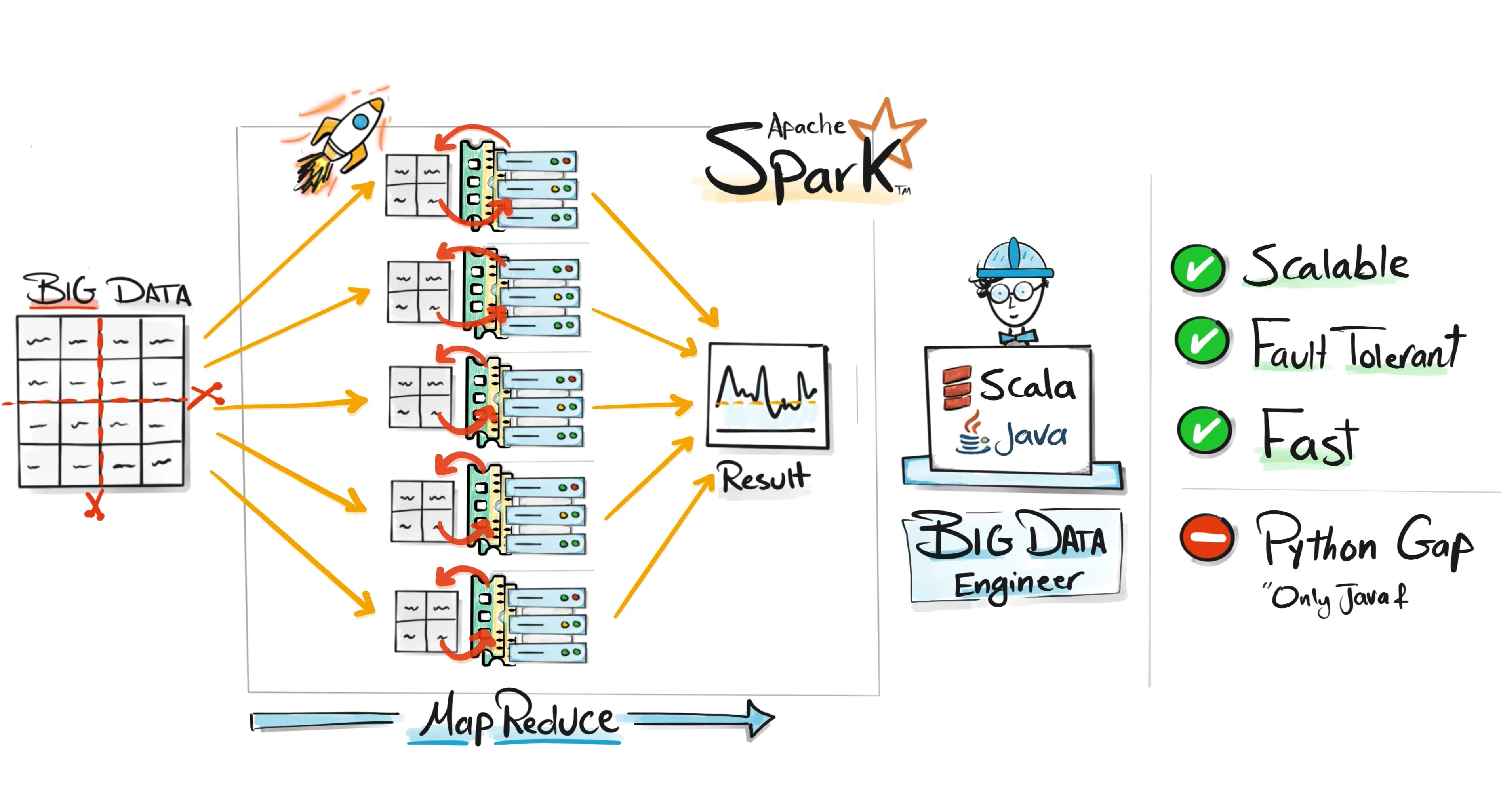
Spark was created to solve the speed problem.
It kept the distributed system idea from Hadoop but changed how computations happened.
Instead of constantly reading and writing to disk, Spark processed data in memory whenever possible.
Memory operations are dramatically faster than disk operations. This made Spark many times faster for most workloads.
Companies quickly adopted Spark as the new standard for big data processing.
But there was another issue.
Early Spark development required knowledge of Scala or Java, which limited who could use it. Most analysts and data scientists were not comfortable with those languages.
Spark made big data fast, but it was still difficult for many data professionals to use.
The PySpark Era
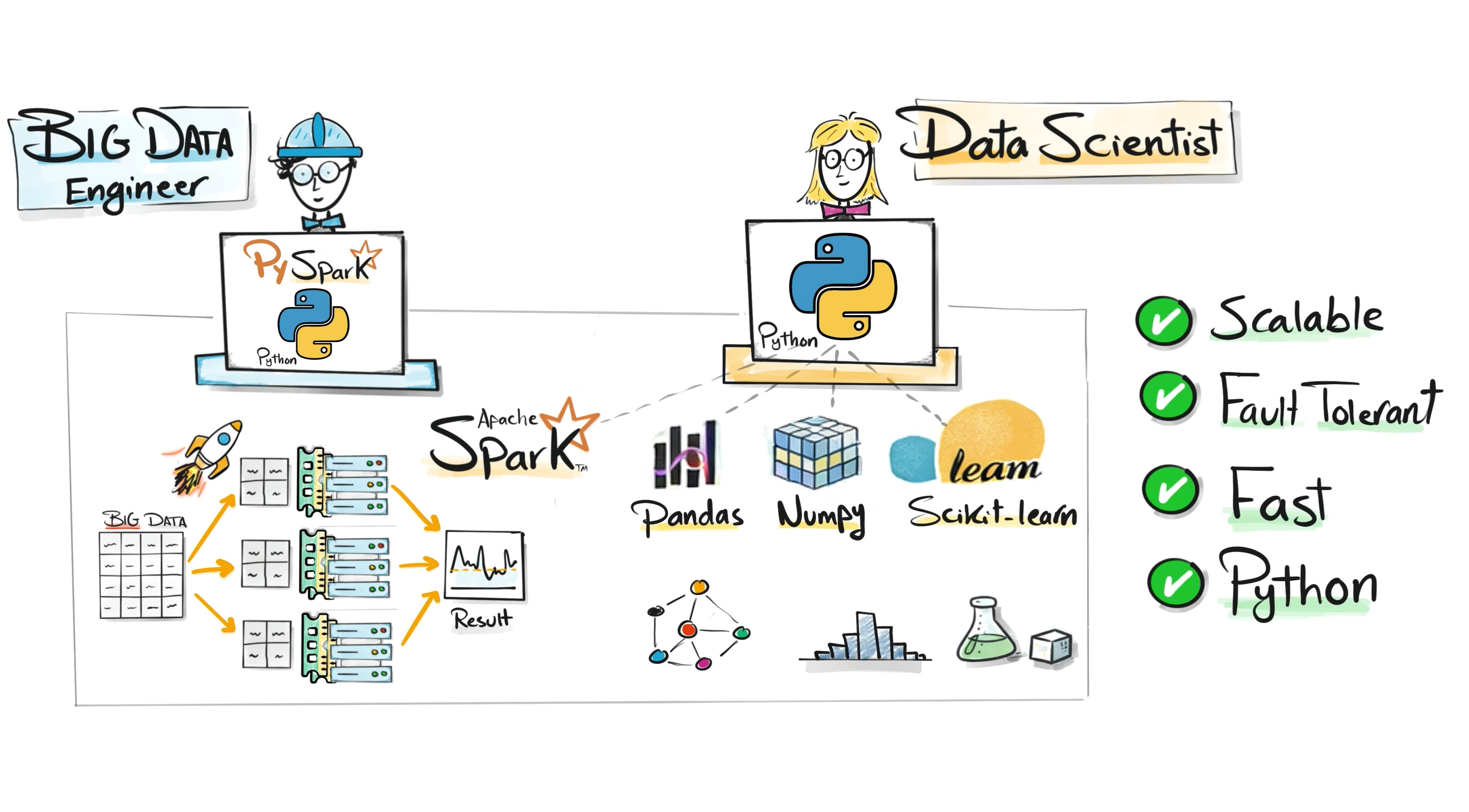
At the same time, Python was becoming the dominant language for data science.
Libraries like Pandas, NumPy, and Scikit-learn made Python extremely popular for data analysis and machine learning.
To connect these worlds, PySpark was introduced.
PySpark allowed developers to write Spark programs using Python while still benefiting from distributed computing.
This opened big data processing to a much larger audience.
However, running Spark at scale was still complicated. Engineers had to configure clusters, manage resources, monitor failures, and handle infrastructure issues.
Before even writing data pipelines, teams often spent weeks setting up the environment.
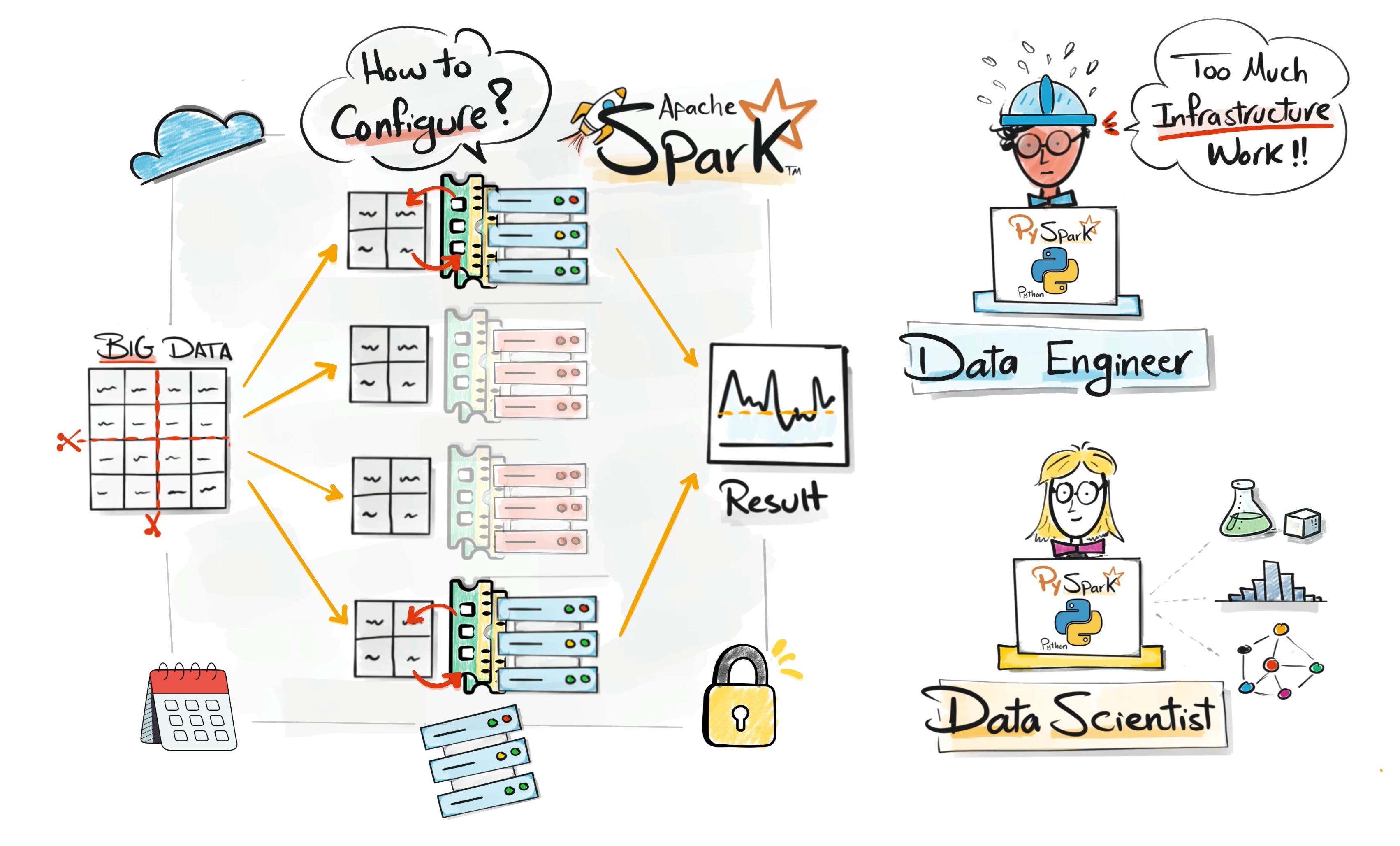
PySpark made big data accessible, but managing the infrastructure remained painful.
Databricks as a Big Data (Managed Spark) Tool
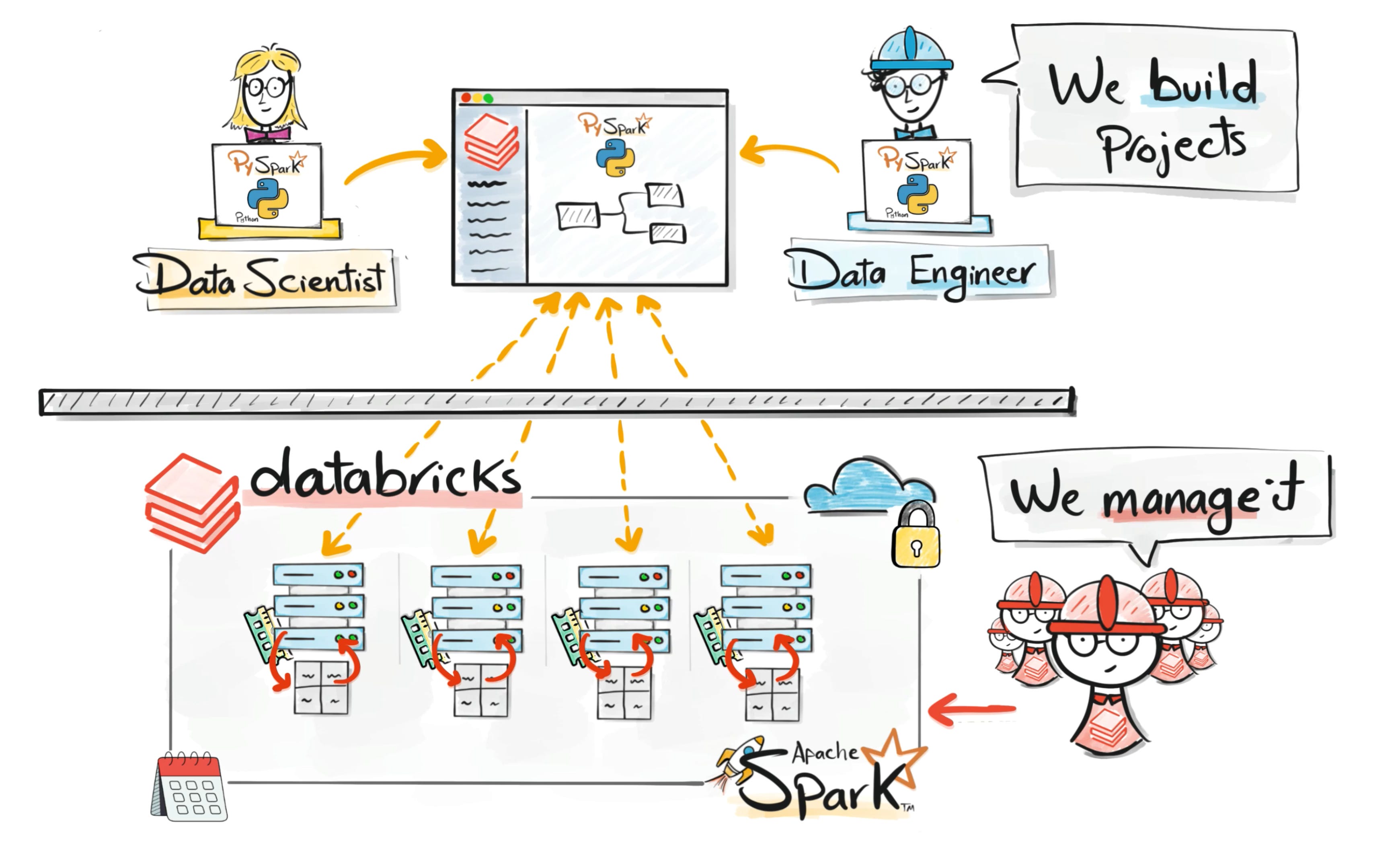
To remove this operational burden, the creators of Spark founded Databricks.
The idea was to provide Spark as a fully managed platform.
Instead of configuring clusters manually, teams could run workloads on a platform where infrastructure, scaling, and environment setup were handled automatically.
This allowed engineers and analysts to focus on building data pipelines, running analysis, and developing models.
But a new problem appeared.
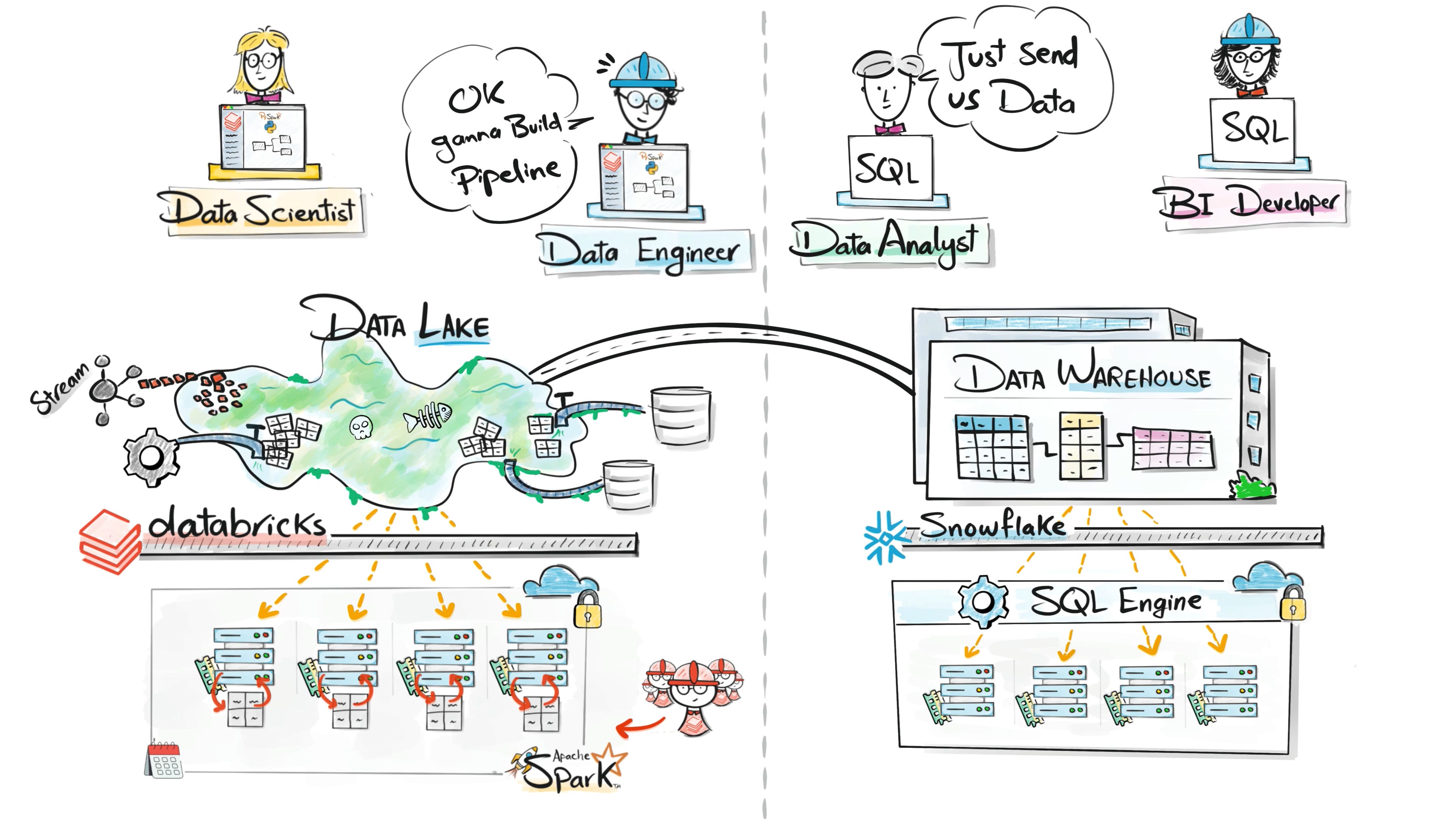
Because storage became cheap and easy, companies began dumping huge amounts of raw data into data lakes.
Over time, many of these lakes became messy. Schemas changed, data quality dropped, and teams lost trust in the datasets.
People started calling them data swamps.
Managed platforms simplified infrastructure, but uncontrolled data lakes created chaos.
Databricks as Data Platform ( Data Lakehouse & SQL)
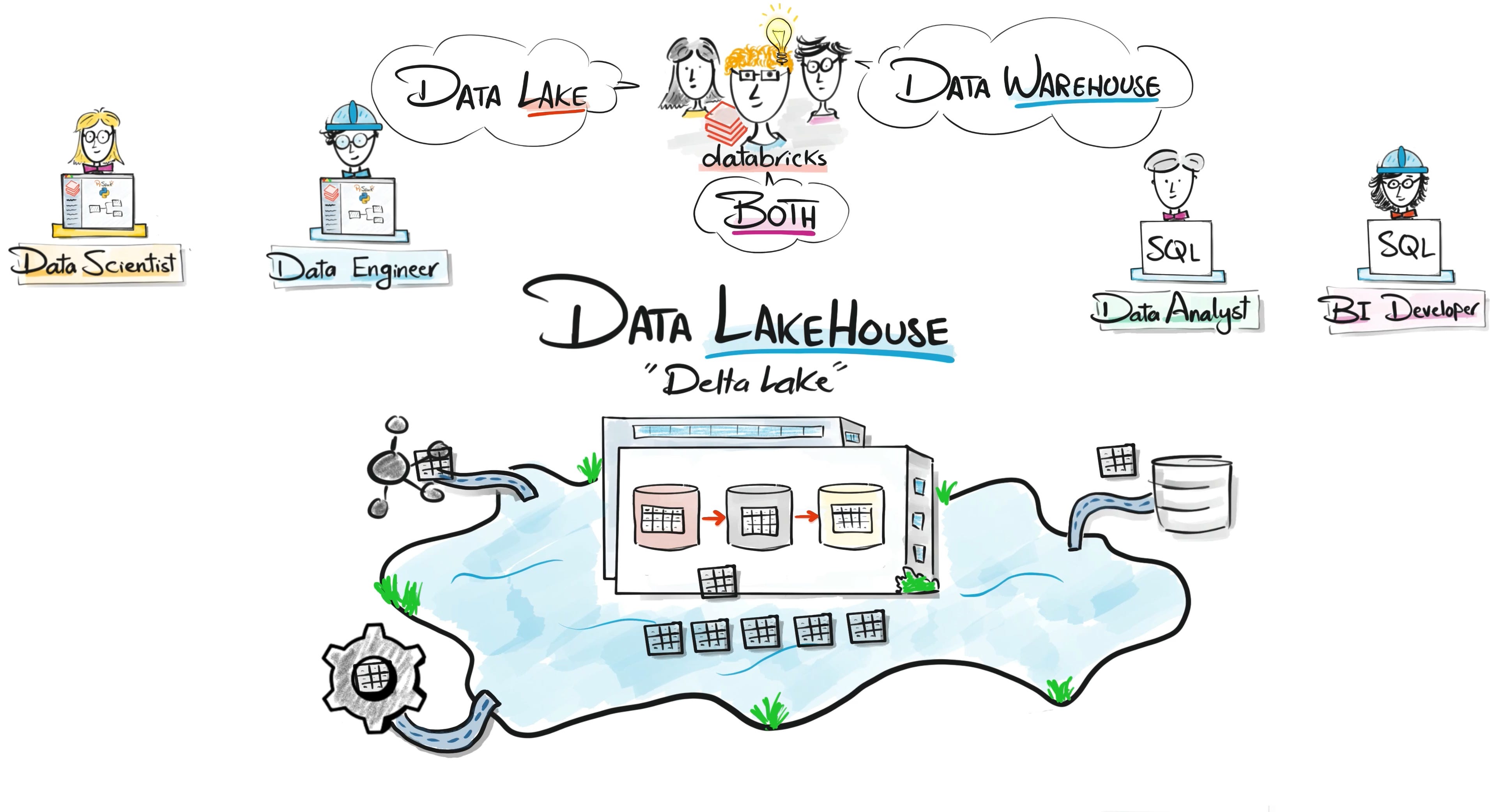
To fix the chaos of data lakes, Databricks introduced the Lakehouse architecture.
The goal was to combine the best parts of two worlds:
Data lakes for scalability and flexibility.
Data warehouses for reliability and structured analytics.
Using technologies like Delta Lake, data lakes gained important capabilities such as transactions, schema enforcement, and versioning.
At the same time, Databricks introduced powerful SQL capabilities, allowing analysts to query the same data layer using familiar tools.
This meant engineers, analysts, and data scientists could all collaborate on the same platform and the same data.
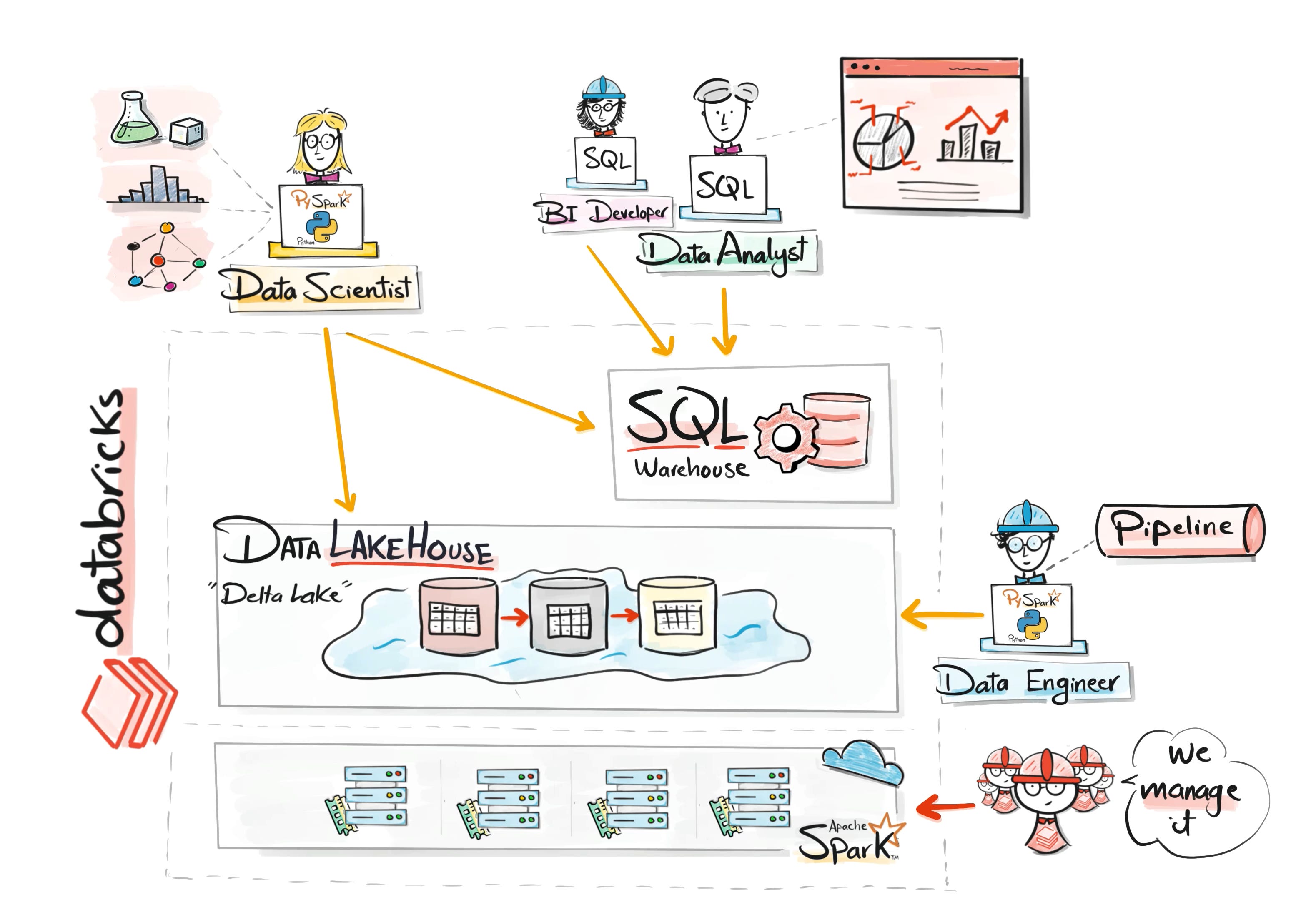
However, as organizations grew larger, another challenge emerged. Data governance.
The Lakehouse unified the data stack, but large organizations needed strong governance.
The Unity Catalog Era
In enterprise environments, managing data access is critical.
Companies must control who can see which datasets, track how data flows across systems, and ensure compliance with regulations.
Without governance, data platforms quickly become risky and unmanageable.
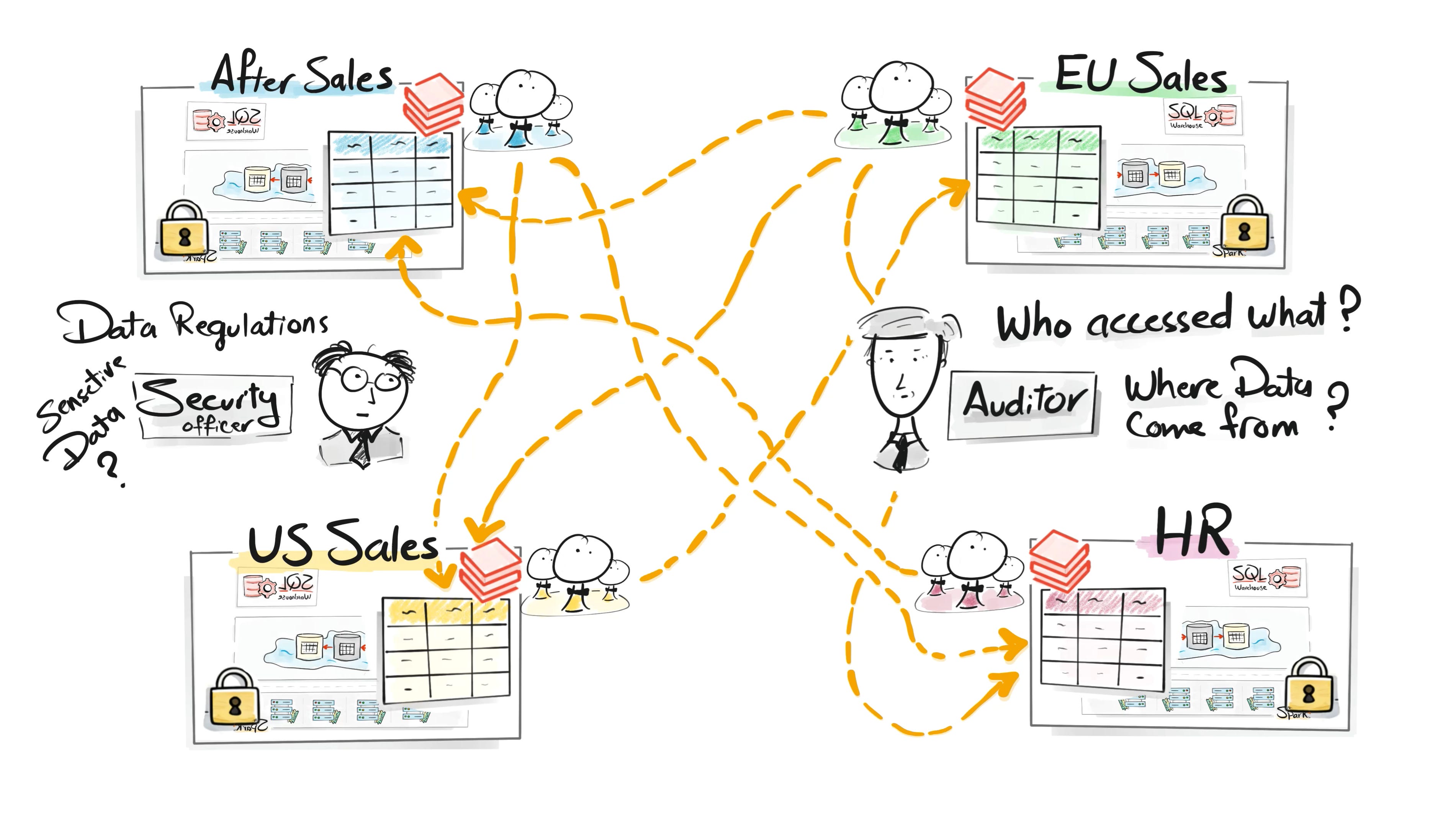
To address this, Databricks introduced Unity Catalog.
Unity Catalog centralizes governance across the platform. It manages catalogs, schemas, tables, permissions, and lineage in one place.
This allows organizations to maintain security, transparency, and compliance while still enabling collaboration.
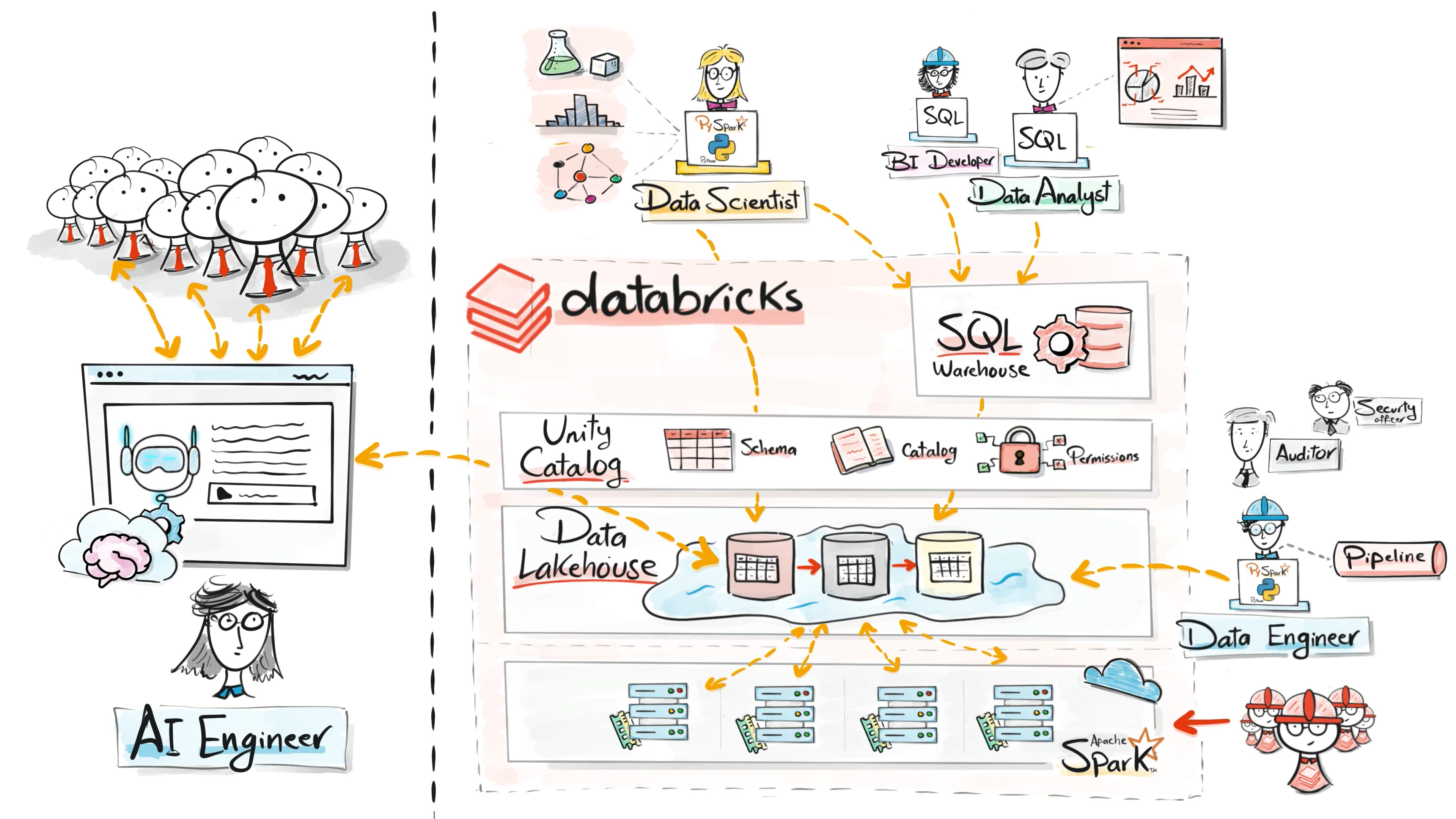
As data platforms scale across organizations, governance becomes essential.
Databricks as Data & AI platform
The industry is now shifting again, this time because of AI.
Companies want to build intelligent systems using their data. But in many organizations a new problem appeared.
The data lived in the data platform, while AI engineers were building systems somewhere else.
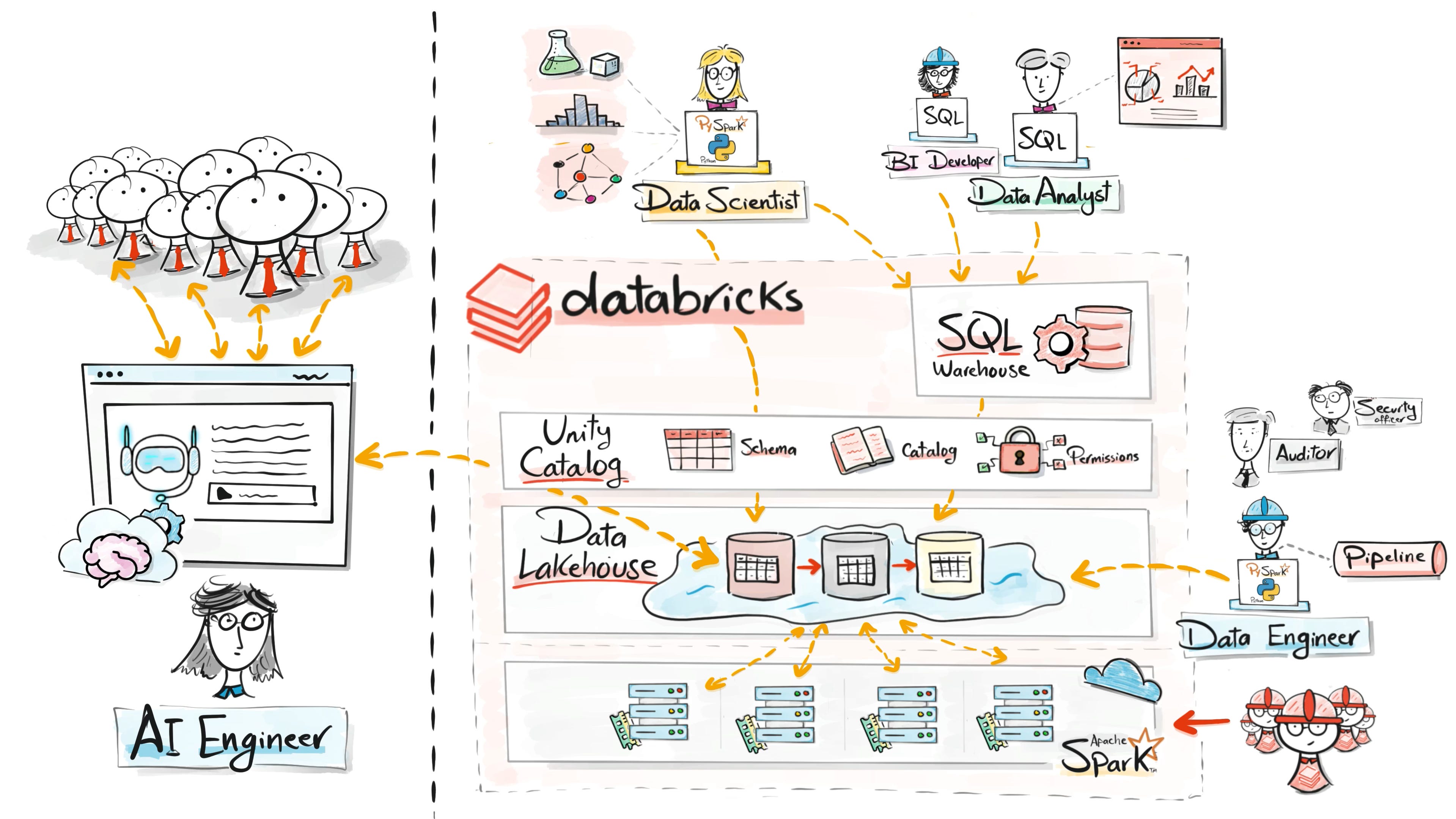
To create AI applications, teams had to build separate infrastructure for model training, LLM integration, and deployment. This created another fragmented architecture.
To solve this, Databricks extended the platform with Mosaic AI.
Mosaic AI allows teams to build, train, and deploy AI systems directly inside the platform, using the same data and infrastructure.
This means data pipelines, analytics, machine learning, and AI applications can now live in one place.
Databricks evolved once again.
Not just into a data platform, but into a Data + AI platform.
The future of data platforms is bringing AI development directly where the data lives.
So …
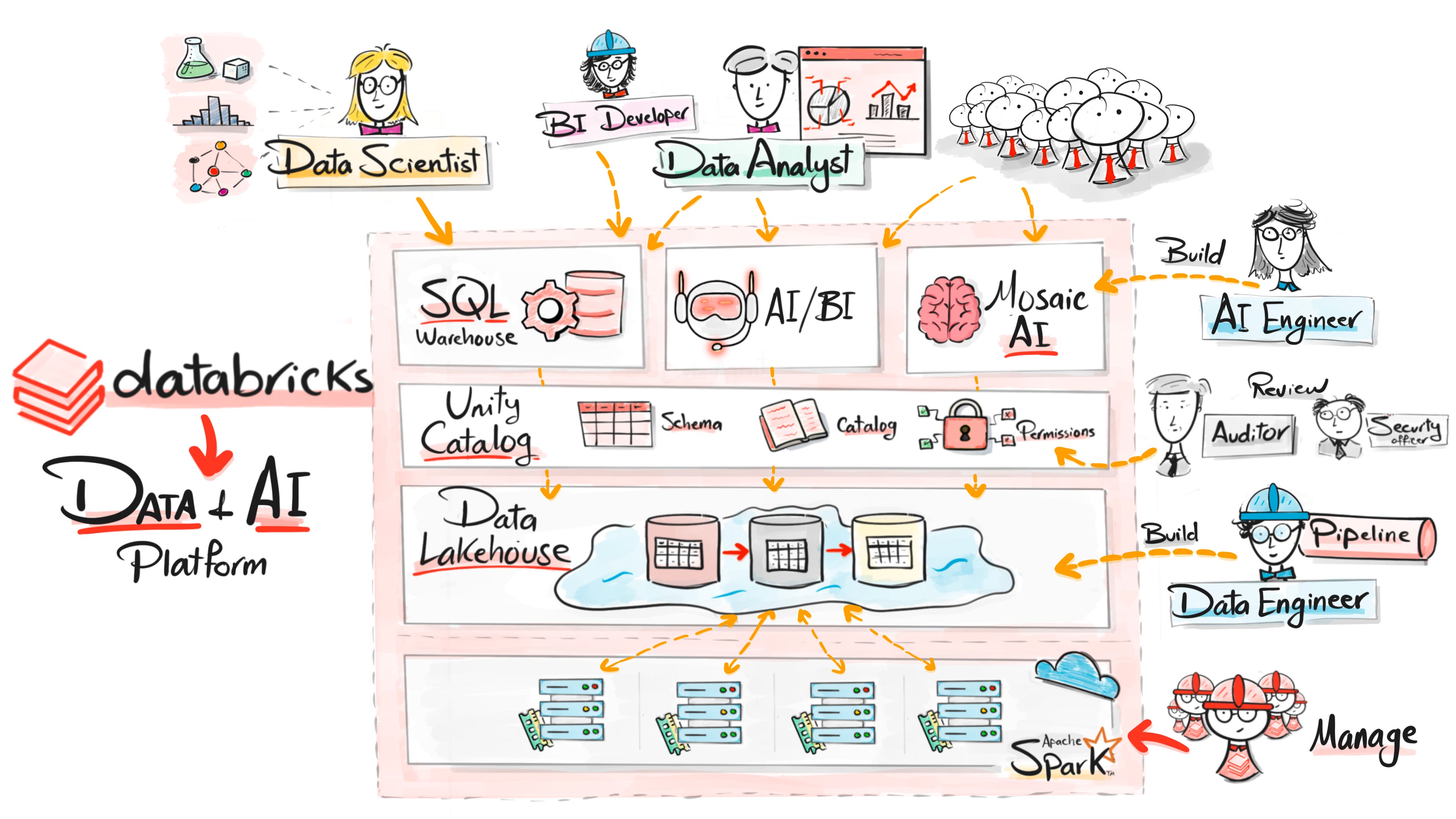
If we step back and look at this entire journey, we can see something interesting.
Every generation of technology solved one major problem.
Single machines worked for small datasets.
Hadoop made it possible to scale to massive data.
Spark made big data processing fast.
PySpark opened the door for Python users.
Databricks removed the complexity of managing infrastructure.
The Lakehouse unified data lakes and data warehouses.
Unity Catalog introduced governance for enterprise environments.
And today the platform continues evolving into a Data + AI platform.
Databricks is a unified platform where data engineering, analytics, machine learning, and AI development happen in one place.
If you want to understand how modern data platforms actually work, join me on YouTube. I’ll be sharing much more content like this in the coming weeks.
The first video is already out, and many more are coming.
Much love,
— Baraa
Also, here are 4 complete roadmap videos if you’re figuring out where to start:
📌 Data Engineering Roadmap
📌 Data Science Roadmap
📌 Data Analyst Roadmap
📌 AI Engineering Roadmap

Hey friends —
Hey, I’m Baraa, a Data Engineer with over 17 years experience, Ex-Mercedes Benz, where I led and built one of the biggest data platforms for analytics and AI.
Now I’m here to share it all through visually explained courses, real-world projects, and the skills that will get you hired. I’ve helped millions of students transform their careers.
Such a great read Baraa!
I learned more about databricks thank you for that !