
AI Engineering Is Just Data Engineering With New Sources
What I figured out after watching it creep into my own projects.

Hey friends, Happy Thursday!
Two, three years ago, when I started hearing about AI engineering, my first reaction was:
“Sounds like a different world. Not for me.”
I was wrong about that. And after seeing how it played out in my own projects, I think a lot of you are sitting in the same spot I was sitting in back then.
Let me walk you through how I figured it out.
How it crept into my own projects
It didn’t happen in one big moment. It happened slowly.
I can tell you from my projects, over time, I started catching myself adding small AI components here and there. A little embedding step. A small retrieval thing. Nothing fancy at first.
And then customers started asking for it. They had real data platforms already, working, in production, and now they were saying:
“Hey, can you extend this with our AI use cases?”
So I found my data platform turning into a data and AI platform. Without me planning it. Without a big strategic decision. Project by project, it just kept happening.
And once I noticed it, I went and looked at the numbers.
This is not the future. It is already happening.
There was a survey from MIT and Snowflake. They asked around four hundred senior data and tech leaders how much time their teams were spending on AI work.
Back in 2023, it was around 19%.
Today it is around 37%.
And in two years, they expect more than 60%.
So no, my friends, this is not the future. This is already happening to us.
The job didn’t get replaced. The job grew a new layer.
And once you understand that, the question is not “do I need to care about AI engineering?”. The question becomes “how do I fit it into what I already do?”
The two-worlds confusion
I get this a lot from messages and comments. People line up the two sides like this.
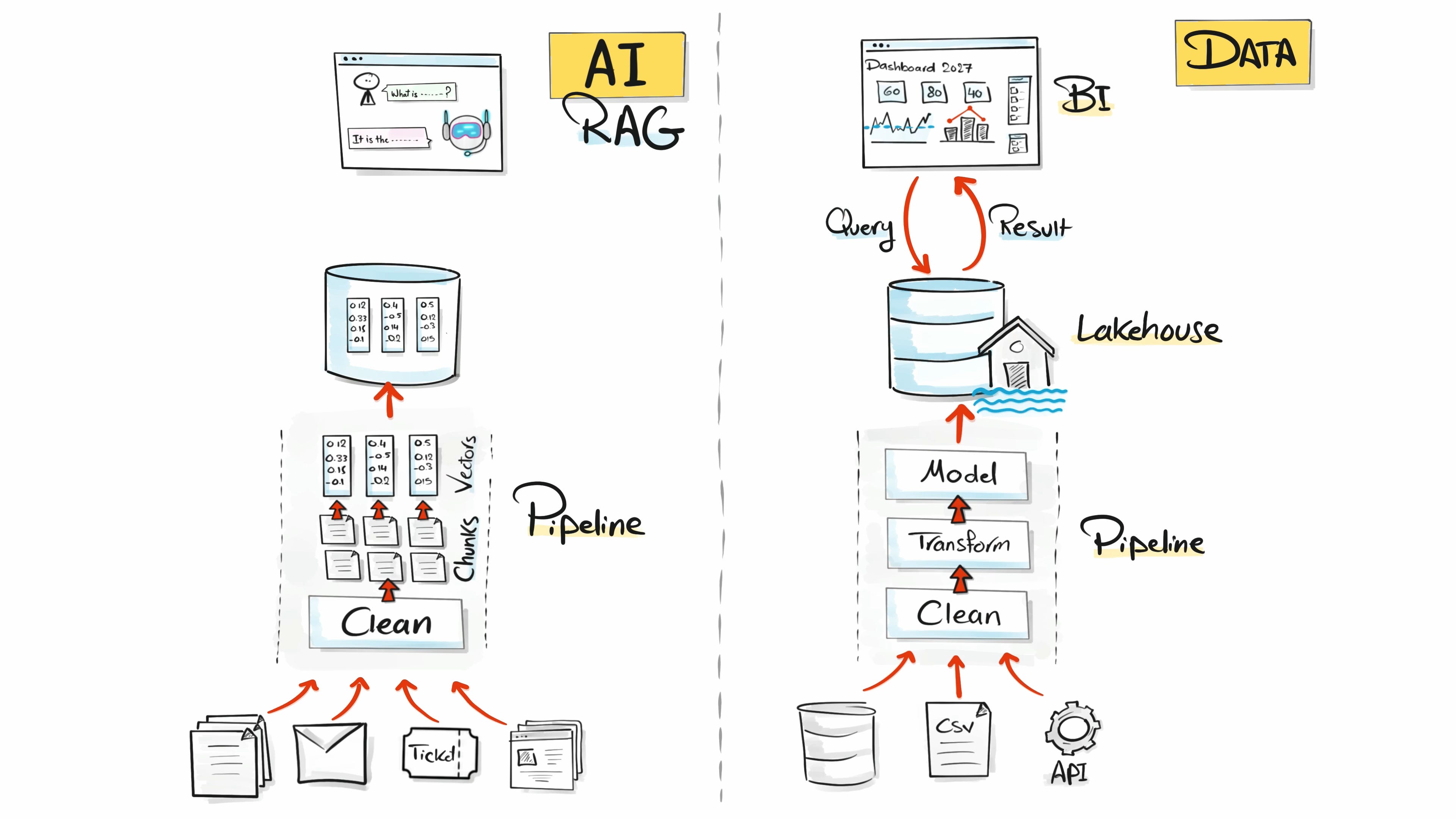
On the data engineering side, we have what we have always done. ETL, data modeling, storage, pipelines, scheduling, data quality, DevOps. The stuff we do every day at work.
On the AI engineering side, suddenly different words. RAG, embeddings, vector databases, prompt engineering, fine-tuning, agents, LLMOps. All shiny, all new, all confusing.
And if you sit back and just look at this split, you say:
“Okay, two different worlds. Nothing to do with me.”
That was my reaction too. But once you look closer, you see something else.
Look closer. Same pattern.
You know how a classical data engineering project flows. Sources (databases, files, APIs), pipeline, warehouse or lakehouse, BI tools and dashboards. You have built it a hundred times.
Sources → Pipeline → Storage → Consumption.
Now look at the AI side. RAG, retrieval-augmented generation, sounds fancy. But the story is the same.
The sources are different. This time it is documents, PDFs, emails, tickets, web pages. The pipeline cleans them, splits them into chunks, and turns them into embeddings. So instead of aggregating, we transform text into numbers. The storage is different too. Instead of a warehouse, we use a vector database. And at the end, the data gets consumed by AI agents and LLMs, that go read it to answer questions with the right context.
Now put both side by side.
Same layering. Different transformations.
That is the moment it clicked for me. AI engineering is not a parallel universe. It is another use case sitting on top of the same skeleton we have been building for years.
Companies don’t build two ecosystems
Now the big practical question. Are companies building two separate platforms? One for data, one for AI?
The honest answer is no.
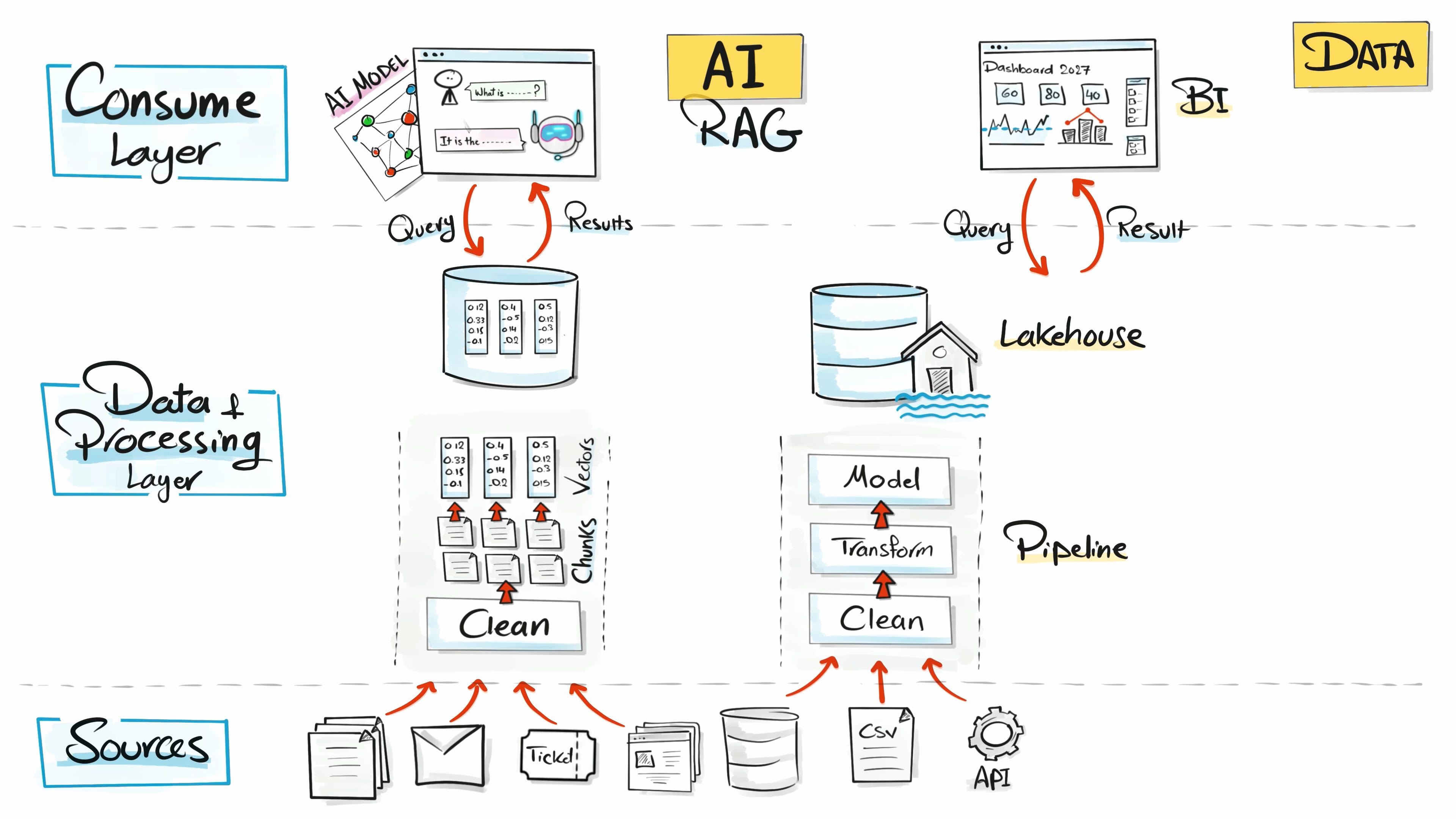
Most of the companies I work with already have solid data engineering projects. They are not going to throw that away and start from scratch. So what they do is they extend the existing platform.
New sources come in. Documents, PDFs, emails, tickets, web pages.
The pipeline grows to handle them, with cleaning, chunking, embedding.
The storage layer gets a new component, the vector database, sitting next to the warehouse and the lakehouse.
And in the consumption layer, AI agents plug in.
So we treat AI use cases like any other data engineering requirement. New sources, new pipelines, new storage, new consumers.
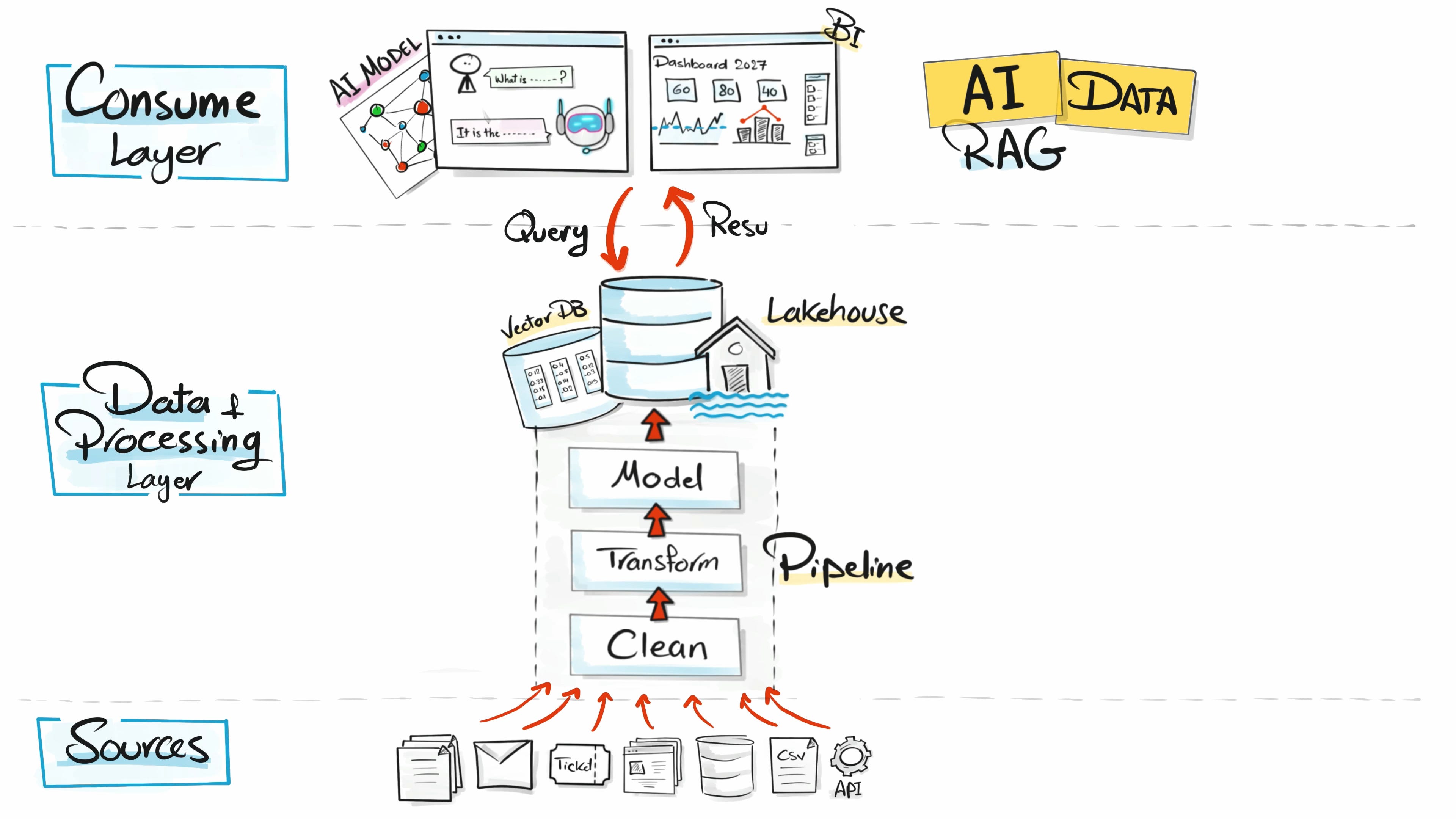
And here is where it gets really good. The AI agent doesn’t only have access to the vector database. It can also reach into the whole lakehouse. All your data is right there.
More data, more context, more use cases.
This is exactly why AI engineering is so close to us. Because the data layer we have been building for years is exactly what AI needs.
So where do AI engineers fit?
Good question, and I get it a lot.
If data engineers can do the whole AI pipeline, why do we even need AI engineers?
Same reason we have data analysts, data scientists, BI developers. We data engineers don’t do the full thing end to end. We pick the source systems, we process the data, we store it in a shape that is easy to consume. And then we stop.
We don’t decide if the users should use Power BI or Tableau. We don’t sit with stakeholders to define business metrics. We don’t go and design the dashboards. That is not our part.
Same with AI. We will not pick which LLM model to use for which use case. We will not design the chatbot interface. We will not build the APIs that the business application calls. All those decisions live on the consumer side.
We own the data processing part. We always did.
Same job. Different consumers.
And honestly, this isn’t the first time we’ve gone through this kind of shift.
ETL → Big Data → Cloud → AI
When I started in this industry, we were called ETL developers. Then the world shifted, and suddenly we were big data engineers, working with Hadoop, MapReduce, all that stuff.
Then the cloud came. Azure, AWS, Databricks, Snowflake. We became modern data engineers.
And now we are in another shift. AI use cases. New sources. New components. New consumers.
But in the heart of the job, my friend, nothing changed.
We move data from A to B. We process it on the way. We make it easy to consume for the next person.
That is what we do. That is what we will keep doing.
So what should you actually do?
You have three options.
Option 1: switch completely. Drop data engineering and become a full AI engineer end to end.
Option 2: ignore the whole thing. Stay where you are, do what you do, hope nobody asks.
Option 3 (this is the one I recommend): stay as a data engineer and add the new AI engineering pieces to your skill set. Combine the two worlds.
And honestly, this is not that hard. You don’t need to become an LLM expert. You just need to learn a few things:
How to connect documents as a source.
How to split text into chunks.
How to turn it into embeddings.
How to store it in a vector database.
How to query a vector database.
That is the RAG pipeline. And it is exactly the kind of work we already know how to think about. Just new components on top of patterns we have used for years.
Put one project like this on your portfolio, and you are already ahead of most data engineers in the market right now.
So …
AI engineering is not a different world. It is the next layer of data engineering.
If you are a data engineer, you are already much closer to it than you think. You just need to extend.
And honestly, I’ll tell you where I think this is going. In two or three years, the job titles will look different. The work will look the same. The people who get hired will be the ones who already extended.
So don’t see AI as a threat. See it as the next chapter of the same job you have been doing all along.
Thanks for reading ❤️
Baraa
Also, here are 4 complete roadmap videos if you’re figuring out where to start:
📌 Data Engineering Roadmap
📌 Data Science Roadmap
📌 Data Analyst Roadmap
📌 AI Engineering Roadmap

Hey friends —
Hey, I’m Baraa, a Data Engineer with over 17 years experience, Ex-Mercedes Benz, where I led and built one of the biggest data platforms for analytics and AI.
Now I’m here to share it all through visually explained courses, real-world projects, and the skills that will get you hired. I’ve helped millions of students transform their careers.
Can’t wait to watch this! @Data with Baraa