
6 Mistakes That Are Stopping You From Becoming a Data Engineer
Most people are doing the right things, just in the wrong way.

Hey friends, Happy Tuesday!
Today we’re going to do something a bit different.
Instead of talking about how to become a data engineer, I want to focus on the mistakes that might be stopping you from getting hired.
Over the last few years, I’ve seen many people move into data engineering. They learn Python, SQL, build projects, follow roadmaps… and still don’t land a job.
Yes, AI made things more competitive.
But companies are still hiring data engineers, even juniors. I see it from your messages, LinkedIn, and inside teams.
So the real question is not whether it’s possible.
“Why do some people succeed while others stay stuck?”
After years in the industry, I can tell you it’s not random. The same mistakes keep repeating.
So in this article, I’ll walk you through the biggest ones, and if you avoid them, things become much easier.
Mistake 1: Trying to Learn Every Tool in the Industry
Trying to learn every tool in the industry. I see this all the time.
Someone decides to become a data engineer and makes a big list of tools to learn.
Kafka, Airflow, Spark, Snowflake, Databricks, AWS, Azure, dbt…
At the end, the roadmap looks like a technology supermarket.
This is a mistake.
If you try to learn everything at the same time, you end up knowing a little about everything, but nothing deeply.
And companies don’t hire you for that. They hire you based on your project experience.
In real projects, you don’t use all those tools. You use a specific stack, like SQL, Python, Spark, Databricks.

And in interviews, they go deep. They expect you to understand the architecture, the components, and how things work.
“If you try to learn everything, you end up mastering nothing.”
So instead of learning 20 tools on the surface, focus on one stack and go deep.
Mistake 2: Focusing Only on Tools
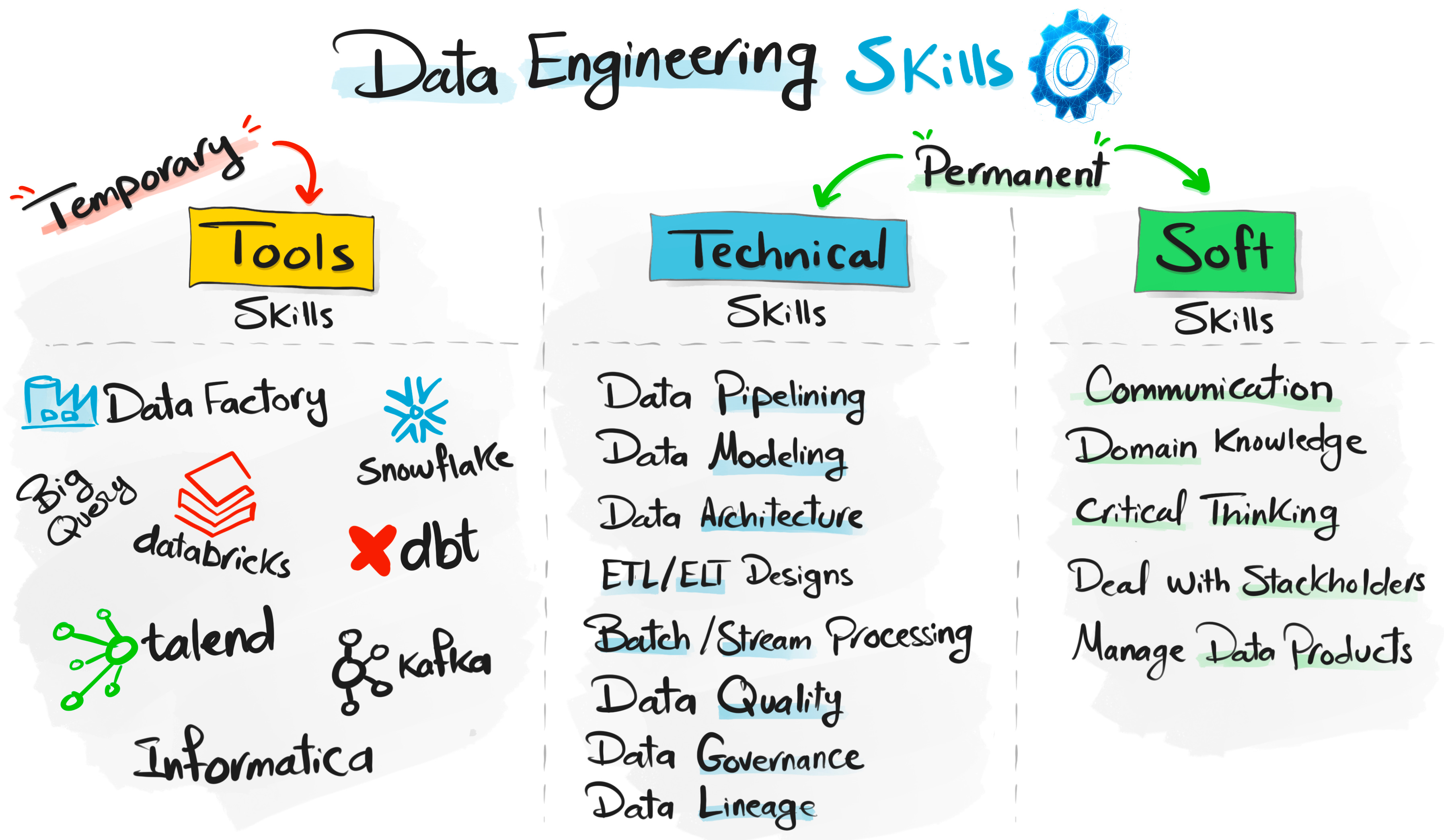
Focusing only on tools and forgetting about the real data engineering skills.
I can tell you from my own experience. Back in 2013, I built my first data warehouse using Talend, then moved to IBM DataStage. Later at Mercedes-Benz, I worked with Azure Data Factory, Synapse, and eventually Databricks.
Different tools, same problems.
That’s the key.
Tools keep changing, but the core concepts stay the same.
If you only learn tools, it becomes very hard to move from one tool to another.
That’s why you need to spend some time understanding the fundamentals.
Things like:
What is a data warehouse, data lake, lakehouse
ETL vs ELT
Batch vs streaming
Data modeling (star schema, snowflake, Data Vault)
You don’t need to master everything, but you should understand what they are and when to use them.
Because companies ask about this.
“Tools change, but concepts stay.”
So yes, learn tools, but also take time to understand how data engineering actually works.
Mistake 3: Ignoring SQL
Ignoring SQL. This one really surprises me.
I’ve seen many engineers who are good with Python and Spark, but they struggle with very simple SQL queries, even basic joins.
A lot of people jump directly into big data tools because they want to work on the “cool” stuff.
But they skip one of the most important skills.
SQL.
And sometimes I hear things like: SQL is dead, it’s not cool, it’s only for beginners.
But this is not true.
In real projects, a huge part of your work still happens in SQL.
Because almost every platform like Databricks, Snowflake, and even tools around Kafka, allow you to use SQL to work with data.
You will use SQL to:
explore data
debug issues
build transformations
apply business logic
For example, in the Silver layer, you might use PySpark, but very often you also use SQL.
In the Gold layer, you will use SQL heavily for business rules.
“If your SQL is weak, your daily work becomes harder.”
So don’t skip SQL. Start with it, get comfortable, then move to Python and Spark.
Mistake 4: Building Toy Projects
Building toy projects.
Projects are very important today. Sometimes they matter more than certificates because they show what you can actually build.
But most of the projects I see are very small. If you look closely, many of them are just loading one CSV file, cleaning it, and exporting another CSV.
Yes, technically it’s a pipeline, but this is not how real data engineering projects look.
In real scenarios, you work with multiple data sources. Data can come from APIs, databases, files, or even streams. And your job is not only to move data from A to B, but also to handle errors, manage retries, validate data quality, and monitor what is happening in the pipeline.
You also need to show how you think in terms of architecture. For example, building a lakehouse with Bronze, Silver, and Gold layers, and explaining the role of each one.
You can also make your project more realistic by adding bad data, testing with larger datasets, and checking how your pipeline performs under pressure.
“Small projects show effort, but real projects show how you think.”
So don’t build many small projects. Build one serious project that looks like a real system.
Mistake 5: Learning Outdated Technologies
Learning outdated technologies.
I’ve seen people follow roadmaps or courses that are already 8 to 10 years old. They spend a lot of time learning things like managing Hadoop clusters, manually configuring Spark, or working heavily with on-premise ETL tools.
Now don’t get me wrong, these things were very important in the past.
But the data ecosystem has changed a lot.
Today, many companies don’t want engineers spending their time managing infrastructure. They want them to focus on building pipelines, working with data, and delivering value.
That’s why many teams are using platforms like Databricks or Snowflake, where most of the infrastructure is handled for you.
So instead of spending months going deep into cluster management and legacy systems, it’s better to focus on how modern data platforms work and how to build real solutions on top of them.
“If you prepare for the past, you might miss where the industry is going.”
Of course, it’s good to understand the basics of older systems, but don’t go too deep into them. Focus on the direction the industry is moving today.
Mistake 6: Going to Extremes with AI
Going to extremes with AI.
Right now, I see two types of people trying to become data engineers.
The first group relies completely on AI. They open a tool, generate a data pipeline, copy the code, run it, and move on without really understanding what is happening.
This becomes a problem very quickly.
In real projects, things are more complex. You deal with multiple data sources, messy data, and unexpected issues. And when something breaks, you need to understand what is going on to fix it.
The same thing happens in interviews. If someone asks you why you designed something in a certain way or how you would debug a failure, it becomes difficult to answer if you were only copying code.
On the other side, there are people who completely ignore AI. They don’t use it at all, don’t know how to write prompts, and don’t take advantage of it.
This is also a mistake.
Today, companies expect engineers to know how to use AI to speed up their work, whether it’s debugging, generating ideas, or improving solutions.
“AI should support your thinking, not replace it.”
So the goal is balance. Use AI as a tool to help you, but make sure you understand what you are building.
So …
These are the mistakes I keep seeing again and again from people who feel stuck and struggle to get hired.
The good part is, none of them are permanent. You can fix all of them.
You don’t need more tools, and you don’t need more random courses.
You need to focus, go deeper, and actually understand what you are building.
If you fix these things, you’ll already be ahead of many others.
“Getting hired is not about doing more, it’s about doing the right things well.”
And if you’re currently searching for a job, I really hope you land one soon.
You’re probably closer than you think.
The first video is already out, and many more are coming.
Much love,
— Baraa
Also, here are 4 complete roadmap videos if you’re figuring out where to start:
📌 Data Engineering Roadmap
📌 Data Science Roadmap
📌 Data Analyst Roadmap
📌 AI Engineering Roadmap

Hey friends —
Hey, I’m Baraa, a Data Engineer with over 17 years experience, Ex-Mercedes Benz, where I led and built one of the biggest data platforms for analytics and AI.
Now I’m here to share it all through visually explained courses, real-world projects, and the skills that will get you hired. I’ve helped millions of students transform their careers.
Thank you Baraa, for telling us how to prepare ourselves to become a data engineer
Thanks Baraa!
Mistake 6 is the most expensive one to get wrong.
Copy the code, skip the understanding, freeze when the pipeline breaks at 3am with no Claude in sight. AI makes the ceiling higher. It also makes the floor disappear faster.